dsds
Banking
The banking industry is evolving in an uncertain global context. Some major change drivers – digitalization, sustainability, regulation, competition – are challenging its ability to optimally satisfy its customers, responsibly act on the markets, comply to stringent regulations and efficiently deliver operations while having to absorb an increasing volume of digital transactions.
Technology
Data analytics and machine learning (often referred to as artificial intelligence), together with big data and real-time frameworks, bring their own promises but often struggle to get productionized in a context where the hype is slowly unveiling the complex data and system architecture that many banking institutions have inherited from the past. Related concerns raise about data fragmentation and data quality, not to speak about legacy technologies and outdated processes.
Data
Financial interbanking transactions appear to be a promising and widely untapped data source presenting key properties:
- Rich content (covers major functional business areas)
- Highly automated and standardized (e.g. ISO1)
- Historically available in big volumes (e.g. billions of records per year per client)
- Real-time available on gateways connected to centralized networks (e.g. SWIFT2, CIPS3, Fedwire4, FIX5)
In terms of monetary value, about 3 trillion dollars is exchanged daily on the SWIFT network only6. SWIFT is also referred to as the “global backbone of financial communication”7. Find more details on the page about financial messaging.
Positionning
The ability to connect and leverage interbanking data at source offers the unique ability of capturing most bank’s I/Os (i.e. inputs/outputs), at least seen from the market side. At that point in the data flow, most business-critical back-office processes can be analyzed, monitored and optimized across business domains and by sourcing data flowing only within a few channels. Also it allows for mirrored analytics approaches, namely by defining methods and metrics that are indifferently applicable to your bank, to your agents, and to your financial institution clients as all of them might well execute similar processes as yours – your I/Os are their O/Is.
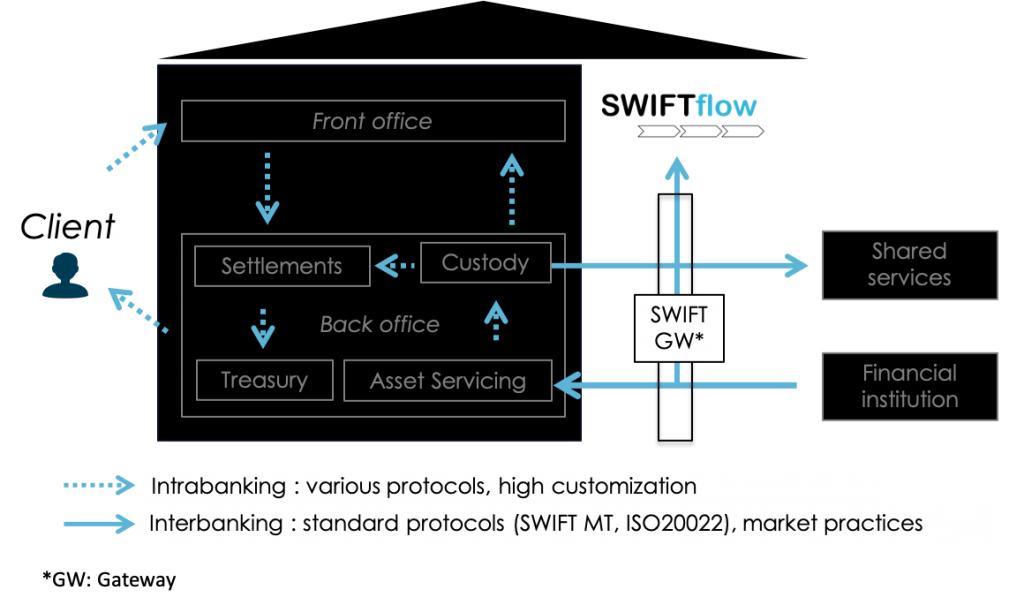
Use cases
At high level, value can be unlocked by Operations analytics with efficiency increase and risk reduction. At lower level, the list of use cases where it can contribute is as broad as banking is. The higher the dependency on the back-office transactional business, the better the coverage of the process with interbanking data. Concrete applications range from payment processing to screening optimization, cash management improvement, securities settlement and asset servicing optimization, but also tax monitoring or know your customer profiling (front or back). Of course interbanking data is not the only vehicle covering the entirety of the information exchanged, nor all the process steps involved. But it can serve as a backbone pipeline that can be extended with side enrichments including non standardized data owned by one specific bank, like client data or product data.
Defining the right use cases and metrics in the client’s context is a key aspect of a successful analytics project.
Reach out to us for more precisions and general consulting : info@alpina-analytics.com.
Challenge
Analytics applications need enough high quality historical data for patterns to be detected. Subsequently, business or statistical rules can be derived by direct human analysis or machine learning. Once those rules or parameters have been learned, they can be applied on real-time streams for prediction, classification or detection tasks, all in a productive context.
Data must be rich to allow for capturing the entirety or at least a good portion of the business process in scope. It must be labeled in case of supervised learning when correct behaviors have to be distinguished from incorrect patterns. It must exhibit some usual pattern in case of unsupervised learning when deviations or outliers are spotted. Holistic capture is ensures that all important attributes or combination of attributes relevant to the modeling task are present. The unused or weak attributes can always be excluded as a next step.
Once captured, data has to be flattened into a tabular format before getting passed as as input to an analyst or to a machine learning model. While that sounds like an easy task when combining a handful of tables retrieved from relational databases, it is a much more demanding task for semi-structured data (think XML or JSON).
Finally, data has to be transformed and enriched into features to bring “some contrast to the pattern”, namely to improve the prediction power of the model or the rule. While some transformations are trivial (say convert a string to an integer), other ones need fully dedicated side processing (like structuring free text data). Some transformations do not need additional context beyond the single message itself and fit to the category of stateless processing. Other kinds of enrichments might need to retrieve short-term historical data (like number of fraudulent transactions per user) for being applicable, and fit into the category of stateful processing.
While being used for a wide variety of transactional applications, the interbanking data is hard to be tapped into for the analytics requirements described, as it shows following characteristics:
- Complex structure with many semi-structured portions (optional fields, nested fields) and unstructured deviations (e.g. free text fields)
- Complex standard with many custom deviations (i.e. bilateral agreement on field usage or regional flavor)
- Fragmentation into business domains, IT applications, and data silos
- Big volumes of data (billions of messages) that are required at analysis time and that need demanding database operations usually out-of-scope for typical on-premise data lake infrastructures
- Real-time processing is required at prediction time (or decisionning time) and puts constraints on streaming processing engines that might be complex to architect on top of legacy platforms and data flows
Solution
The goal of Swiftflow is to unlock interbanking data and make it available for data analytics applications. It articulates at pipeline level and at platform level:
- It is a data transformation pipeline that transforms data into a data model tailored for downstream analytics applications, namely by parsing, enriching, structuring, and enabling advanced grouping of those transactions
- It is natively thought to be integrated on cloud platforms, where planet-scale database and streaming data engines can elastically apply to the large and complex transformations in scope, and where demanding machine learning can be performed
More details on Swiftflow features here and on cloud integration here.
Sources
- https://www.iso.org/news/ref2483.html
- https://en.wikipedia.org/wiki/Society_for_Worldwide_Interbank_Financial_Telecommunication
- https://en.wikipedia.org/wiki/Cross-Border_Inter-Bank_Payments_System
- https://en.wikipedia.org/wiki/Fedwire
- https://en.wikipedia.org/wiki/Financial_Information_eXchange
- www.swift.com
- https://www.iso.org/news/ref2483.html